Joining / Merging Data
Relational Data
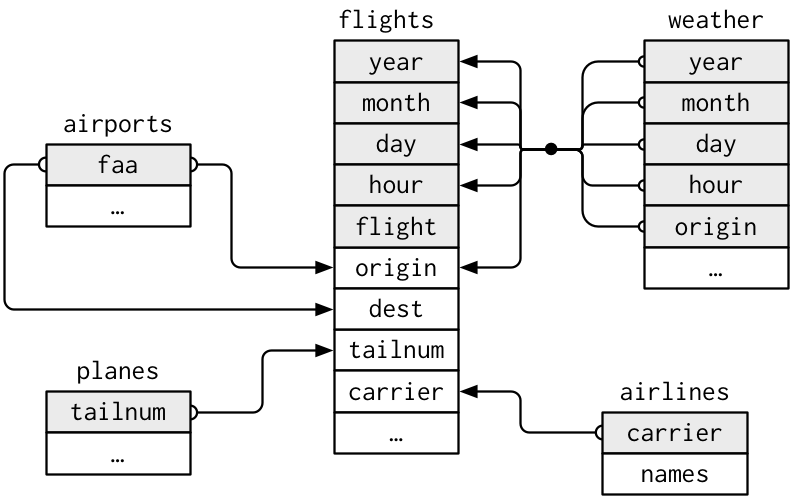
Visualizing Relational Data
- Primary key: uniquely identifies an observation in its own table. For example,
planes$tailnumis a primary key because it uniquely identifies each plane in the planes table. - Foreign key: uniquely identifies an observation in another table. For example, the
flights$tailnumis a foreign key because it appears in the flights table where it matches each flight to a unique plane.
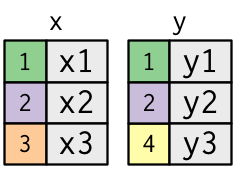
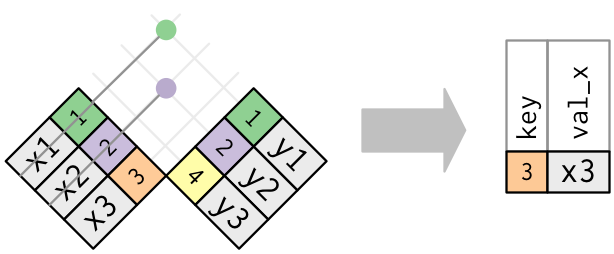
Inner Join
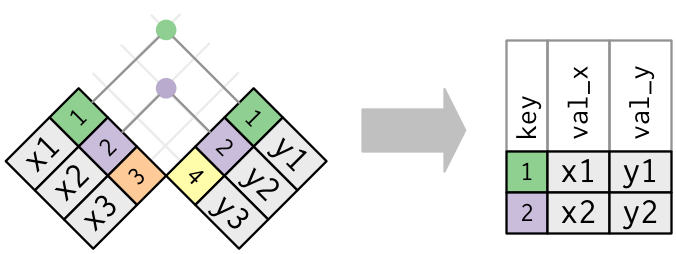
Matches pairs of observations whenever their keys are equal:
Outer Joins
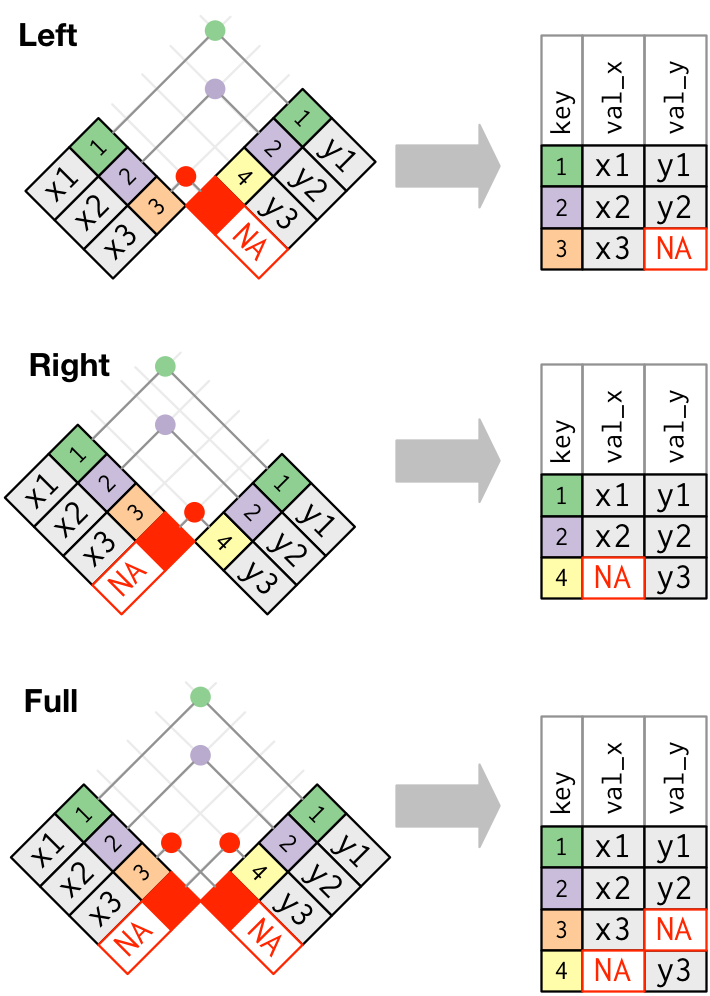
Outer Joins: another visualization
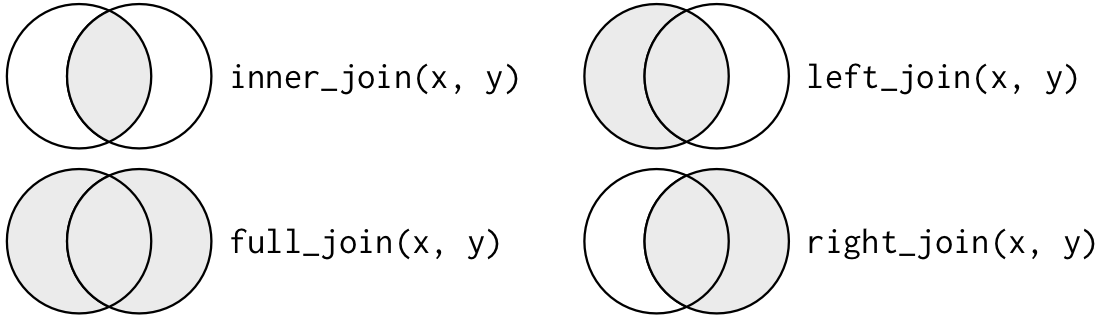
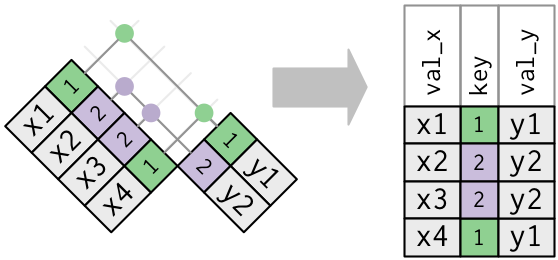
Duplicate Keys
One table w/ duplicates
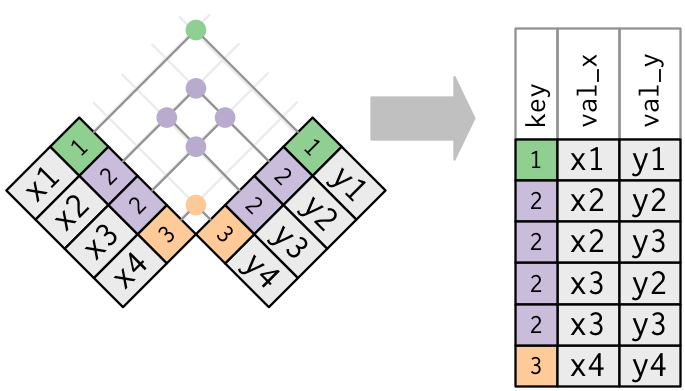
Duplicate Keys
Both tables w/ duplicates
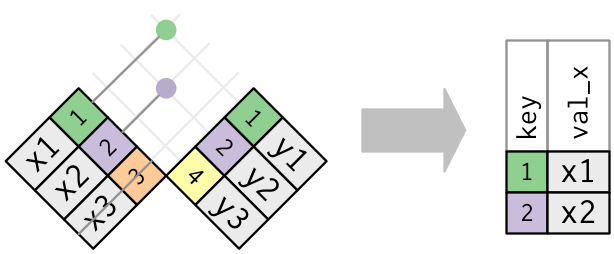
Missing Keys
semi_join(x, y) keeps all observations in x that have a match in y.
anti_join(x, y) drops all observations in x that have a match in y.
Anti-joins are useful for diagnosing join mismatches.